2019/09/18
RailsでAmazonTranscribeを使ってみよう
はじめに
おはようございます。早起きチャレンジに成功した宇賀神です。
最近AWSの文字起こしサービスである AmazonTranscribe を少し触る機会があったので、今日はそのあたりのお話。
実行環境
ruby 2.6.2
rails 5.2.3
What is Transcribe
この辺読んでもらうのが早そうですが、簡単に解説。
2017年11月29日に発表された、 Speech to Text と呼ばれる機能を提供する自動音声認識サービスです。
mp3ファイルなどを投げると文字起こしされたjsonが返ってくる、といった感じです(ざっくり)。
実装、の前に
aws側の準備をしましょう。
transcribeの実行にはS3が必要になるのでサクッとバケットを作っておきましょう。バケットを作成したら、元となるmp3ファイルを置いておきましょう。
また、ruby側でsdkから使用するIAMも用意する必要があります。
注意
S3のリージョンはtranscribeのリージョンと揃える必要がありますが、transcribeは2019年9月現在、東京リージョンに対応していません。他のアジア圏のリージョンを使用するか、料金の安いバージニア辺りを使うのが良さそうです。
実装
手順としては以下の通り
- gemの準備
- .envの準備
- コードを書く
ではいってみましょう。
gemの準備
下記をGemfileに記述して、bundle installをしましょう。
S3のアップロードからやる場合は aws-sdk-s3 も追加しておきましょう。
gem 'aws-sdk-transcribeservice'.envの準備
.envに以下を設定します。
AWS_S3_BUCKET="my-s3-bucket-name"
AWS_REGION="us-east-1" # バージニア
AWS_ACCESS_KEY_ID="XXXXXXXXXXXXXXXXX"
AWS_SECRET_ACCESS_KEY="xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"コードを書く
今回は簡単にrails runnerで実行できるよう実装します。
アプリケーション内で実行して使う場合は、いい感じに応用してください。
lib/runners/amazon_transcribe.rb 的なファイルを用意して、以下のような感じに
job_name = ARGV[0]
media_file_uri = ARGV[1]
client = Aws::TranscribeService::Client.new(
region: ENV['AWS_REGION'],
access_key_id: ENV['AWS_ACCESS_KEY_ID'],
secret_access_key: ENV['AWS_SECRET_ACCESS_KEY']
)
response = client.start_transcription_job(
transcription_job_name: job_name,
language_code: 'en-US',
media_format: 'mp3',
media: {
media_file_uri: media_file_uri
},
output_bucket_name: ENV['AWS_S3_BUCKET']
)
puts responsejob_name(ARGV[0]) には作成するjobの名前を、 media_file_uri(ARGV[1]) にはS3に置いたmp3ファイルのuriをそれぞれ渡してあげます。実行コマンドは以下のような感じ。
$ rails runner lib/runners/amazon_transcribe.rb test-job s3://my-s3-bucket-name/media.mp3
実行してからtranscribeのダッシュボードを確認すると、以下のようなjobが作成されているかと思います。
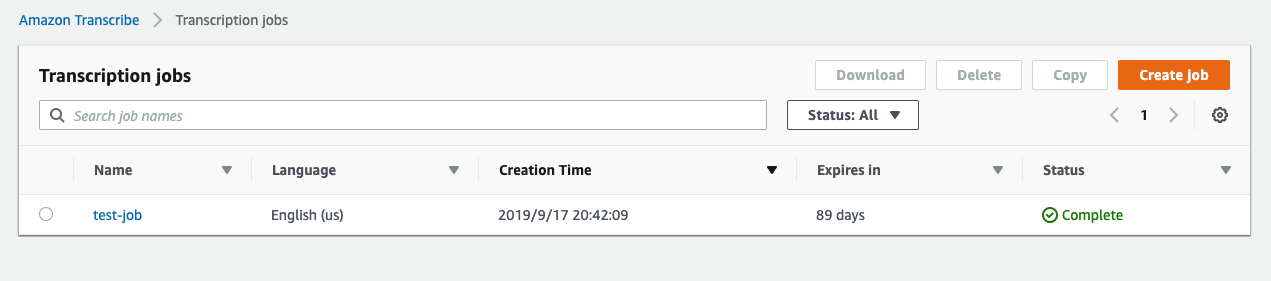
status が Complete なったのちに、S3を確認してみてjsonが保存されていれば、実験成功です。
まとめ
ちょっと駆け足でしたが、Amazon Transcribeの紹介でした。
クラウドサービスで文字起こしってちょっと前まで選択肢にもないような手段でしたが、だいぶ簡単にできるようになってましたね。awsすごい。
また更新します〜〜